
前言
机器学习的目标是使得我们模型的泛化能力足够强,因此我们需要有衡量模型泛化能力的评价标准。对不同种类的机器学习问题,评价标准不一样。回归问题常用均方误差(MSE)、绝对误差(MAE)等评价指标,分类问题评价指标则较多,如下图所示。本文主要讲解分类问题的评价指标。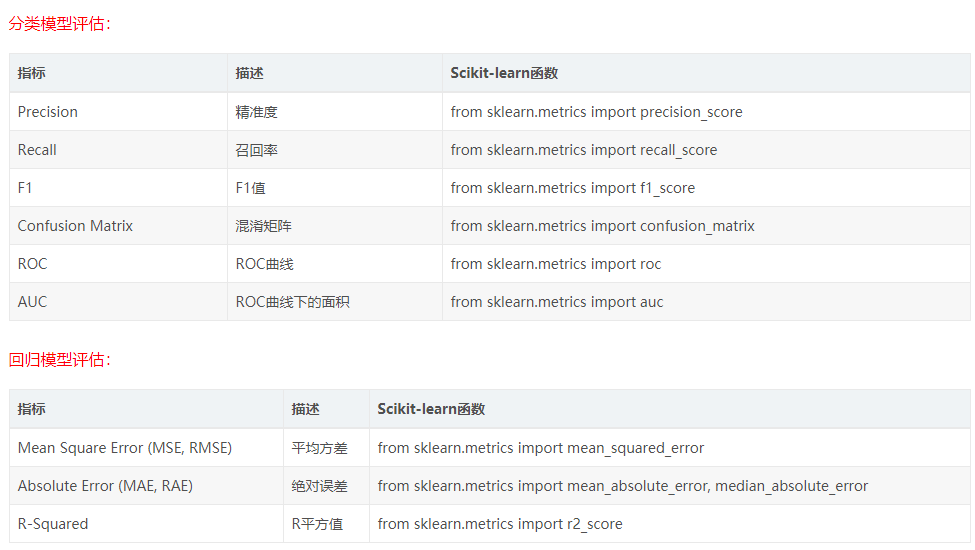
二分类问题中常用的概念
首先解释几个二分类问题中常用的概念:True Positive, False Positive, True Negative, False Negative。它们是根据真实类别与预测类别的组合来区分的。
假设有一批测试样本,只包含正例和反例两种类别。则有:
- 预测值正例,记为P(positive)
- 预测值为反例,记为N(Negative)
- 预测值与真实值相同,记为T(True)
- 预测值与真实值相反,记为F(False)

上图左半部分表示预测为正例,右半部分预测类别为反例;样本中的真实正例类别在上半部分,下半部分为真实的反例。- TP: 预测类别为正,真实类别也为正例;
- FP:预测类别为正例,真实类别为反例;
- FN:预测为反例,真实类别为正例;
- TN:预测为反例,真实类别也为反例;
精确率(precision)
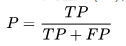
精确率是针对我们模型预测的结果而言的,它表示的是预测为正的样本中有多少是真正的正样本;
故分子为TP,而预测为正有两种可能:真正(TP)和假正(FP),即为分母。
召回率(recall)
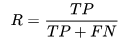
召回率是针对原始样本而言的,表示样本中的正例有多少被预测正确了,故分母应表示所有的原始样本;
F1值
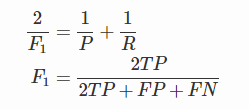
F1值是精确率和召回率的调和均值,当P和R值都高时,F1值也会高。
ROC、AUC
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)。对于计算ROC,有三个重要概念:TPR,FPR,截断点。
TPR即 True Positive Rate,表示真实的正例中,被预测正确的比例,即TPR = TP/(TP+FN);
FPR即 False Positive Rate, 表示真实的反例中,被预测正确的比例,即FPR = FP/(TN+FP);
很多ML算法是为test样本产生一个概率预测,然后将这个概率预测值与一个分类阈值(threhold)进行比较,若大于阈值则分为正类,反之为负类。这里的阈值就是截断点,比如对算出测试样本A为正类的概率为0.3,低于截断点0.5,于是将A分为负类。
截断点取不同的值,TPR和FPR的计算结果也不同。将截断点不同取值下对应的TPR和FPR结果作图得到的曲线,就是ROC曲线。横轴是FPR,纵轴是TPR。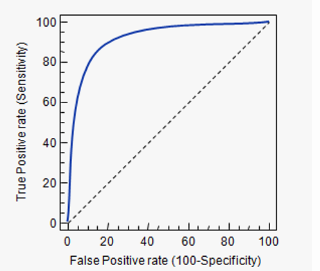
若比较两个算法的优劣,可以看哪个曲线能把另一个完全包住;或者计算曲线的面积,即AUC的值。
ROC经常用于样本类别不均衡的二分类问题。
sklearn实现roc、auc
1 | from sklearn.metrics import roc_curve, auc |
