
前言
As all we know, 线性代数对于机器学习的重要性不言而喻。但纵观国内的教材和课程,大部分线性代数的讲解,一上来就堆满了各种定义和公式,从而导致我们知其然而不知其所以然,不利于我们深入理解机器学习的算法。
因此,希望本篇博文能帮大家从另一个角度理解线性代数。但是注意,阅读本篇博文,最好已经有了线性代数的基础,比如要知道矩阵的形式,矩阵怎么相乘之类的基础知识。然后如果你虽然知道矩阵相乘怎么算,却并不知道它们有什么物理含义,那么相信本篇博文会让您有所收获。本系列博文分为上下两篇,上篇主要讲矩阵的本质,下篇主要讲向量的范数和矩阵分解。
矩阵的本质(一)
1、矩阵本质上就是映射、变换
比如,对于空间A中的一个三维点a(a1,a2,a3),空间B的一个二维点b(b1,b2),那么如何将a点映射成b点呢?只需构造一个维度为3*2的矩阵,利用矩阵乘法便可实现映射。
矩阵的本质就是描述空间的映射。因此它可以看作一个函数,接受一个空间作为输入,输出一个映射后的新空间。
2、各种矩阵运算的本质是什么?
- 加法:矩阵的加法就是映射规则的调整。矩阵A+矩阵B就可以看作,用B中各个元素的值去调整A这个映射规则。
- 乘法:矩阵的乘法表示线性映射的叠加。
比如,我们已经知道矩阵A可以从X空间映射到Z空间,矩阵B可以从Z空间映射到Y空间,那么怎么从X空间映射到Y呢?答案就是矩阵乘法A*B。 - 逆运算:矩阵的逆运算就是映射的逆映射;这里我用一个NLP的例子来解释,比如在一个机器翻译问题中,源语言在X空间,目标语言在Y空间,我们通过训练知道了如何从X空间映射到Y空间,即通过训练得到了映射矩阵A。那么我们如何反向翻译呢?那就是求A的逆矩阵就可以了,完全无需再反向重新训练。
3、特殊矩阵的含义(从映射角度理解)
- 零矩阵就是将任何空间映射成原点的矩阵;
- 单位矩阵就是将任何空间映射成自己的矩阵;
- 对角矩阵就是将原空间的各个坐标轴进行不同尺度的拉伸或挤压后生成新空间的矩阵;
比如任何一个二维空间乘上一个对角矩阵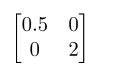 后,这个空间第一个维度(每一列表示一个维度)上的坐标轴会缩短为原来的一半,第二个维度的坐标轴会膨胀成原来的两倍!假设这个二维空间中的点(2,2)经过这个对角矩阵的映射后,会变成(1,4)。
后,这个空间第一个维度(每一列表示一个维度)上的坐标轴会缩短为原来的一半,第二个维度的坐标轴会膨胀成原来的两倍!假设这个二维空间中的点(2,2)经过这个对角矩阵的映射后,会变成(1,4)。4、矩阵分块的意义
矩阵分块对应的算法思想就是分治,一个最重要的应用就是并行化矩阵运算,这也是深度学习中最离不开的底层运算。
设想一下,一个10000*10000维的超大矩阵再乘以另一个10000*20000维的超大矩阵,如果让一个单核CPU去计算的话,可能CPU会崩溃!我们知道,在深度学习任务中,由于参数非常多,数据维度也很高,因此进行大矩阵运算是家常便饭。同时,我们之所以喜欢用GPU去训练深度学习任务,一个很重要的原因是GPU的“核”很多,经常几百几千,甚至几万核,非常利于并行计算。因此,在深度学习中,通过将大矩阵分块,分成若干个小块,再将这些小块丢进GPU成千上万的核里并行计算,那么转瞬间就可以完成这个大矩阵的计算。矩阵的本质(二)
1、从存储数据的角度
矩阵A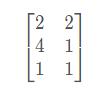 就是存储数据的作用了。矩阵的每一行表示空间中的一个样本点,所以A就表示二维空间里的三个样本点;如果将A这三个样本点丢给映射W
就是存储数据的作用了。矩阵的每一行表示空间中的一个样本点,所以A就表示二维空间里的三个样本点;如果将A这三个样本点丢给映射W ,就得到了三个样本点在新空间上的新空间上的镜像点A x W =
,就得到了三个样本点在新空间上的新空间上的镜像点A x W =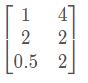
在神经网络中,每一层的输出经过权重矩阵,映射到下一层的输入过程,就是上述过程。2、特征值与特征向量的物理意义
我们将矩阵W重新夸张一下W=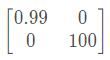 那么这个映射就代表将第一维度压缩为原来的0.99倍(几乎无变化),将第二维度拉伸为原来的100倍(变化很大)。这个映射的作用对象很明显:
那么这个映射就代表将第一维度压缩为原来的0.99倍(几乎无变化),将第二维度拉伸为原来的100倍(变化很大)。这个映射的作用对象很明显:- 第一维度坐标轴。在二维空间中,第一维度坐标轴不就是x轴嘛,所以我们可以用单位向量(1, 0)表示;
- 第二维度坐标轴。同理,第二维度可表示为(0, 1);
显而易见,W映射对每个作用对象的作用程度明显不一样:对第一维度作用小,对第二维度作用大;
升华一下,上述的作用对象就是所谓的特征向量,“对某作用对象的作用程度” 就是特征值。因此,一个矩阵或一个线性映射,完全可以用它的全部特征值与其对应的特征值去描述!(这里指方阵);而将矩阵分解为它的特征值与特征向量的过程被称为“特征分解”,特征矩阵分解是众多矩阵分解中的一种,因此原矩阵A就会被分解成几个目标矩阵了,这里的目标矩阵有两个,一个是由特征向量组成的,另一个是由特征值组成的;3、标量、向量、张量之间的联系
- 张量(tensor)
在某些情况下,我们会讨论坐标超过两维的数组。一般地,一个数组中的元素分布在若干维坐标的规则网格中,我们将其称之为张量。使用粗体A来表示张量“A”。张量A中坐标为(i,j,k)的元素记作A(i,j,k)。 - 关系
标量是0阶张量,向量是一阶张量。 举例:
标量就是知道棍子的长度,但是不知道棍子指向哪儿;
向量就是不但知道棍子的长度,还知道棍子指向前面还是后面;
张量就是不但知道棍子的长度,也知道棍子指向前面还是后面,还能知道这棍子向上/下和左/右偏转了多少。4、张量与矩阵的区别
- 从代数角度讲,矩阵是向量的推广。向量可以看成是一维的“表格”(即分量按照顺序排成一列),矩阵是二维的“表格”(分量按照纵横位置排列),那么n阶张量就是所谓的n维的“表格”,故可以将矩阵视为二阶张量。张量的严格定义是利用线性映射来描述的。
- 从几何角度讲,矩阵是一个真正的几何量,也就是说,它是一个不随参照系的坐标变换而变化的东西。向量也具有这种特性。
- 矩阵是张量的一个切片。
- 张量是矩阵基础上更高维度的抽象,简而言之,张量囊括一切。
