
前言
在机器学习中的线性代数知识(上)一文中,主要讲解了矩阵的本质,以及映射视角下的特征值与特征向量的物理意义。本篇博文将继续讨论相关知识。
向量和矩阵的范数归纳
1、向量的范数
这里我直接以实例讲解。定义一个向量为:a=[-5, 6, 8, -10]
向量的1范数:向量的各个元素的绝对值之和,上述向量a的1范数结果就是:29;
向量的2范数:向量的每个元素的平方和再开平方根,上述a的2范数结果就是:15;
向量的负无穷范数:向量的所有元素的绝对值中最小的。上述向量a的负无穷范数结果就是:5;
向量的正无穷范数:向量的所有元素的绝对值中最大的。上述向量a的正无穷范数结果就是:10;
2、矩阵的范数
定义一个矩阵A=[-1 2 -3;4 -6 6];
矩阵的1范数:矩阵每一列上的元素绝对值先求和,再从中取最大值(列和最大)。上述矩阵A的1范数就是9;
矩阵的2范数:矩阵$A^TA$的最大特征值开平方根,上述矩阵A的2范数就是:10.0623;
矩阵的无穷范数:矩阵的每一行上的元素绝对值先求和,再从中取个最大的(行和最大),上述矩阵的结果就是:16;
矩阵的核范数:矩阵的奇异值之和(将矩阵SVD分解,文章后面会讲到),这个范数可以用低秩表示(因为最小化核范数,相当于最小化矩阵的秩——低秩),上述矩阵A最终结果就是:10.9287;
矩阵的L0范数:矩阵的非0元素的个数,通常用它来表示稀疏性,L0范数越小0元素越多,也就越稀疏,上述矩阵A的最终结果就是:6;
矩阵的L1范数:矩阵中的每个元素绝对值之和,它是L0范数的最优凸近似,因此它也可以表示稀疏,上述矩阵A最终结果就是:22;
矩阵的F范数:矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数。上述矩阵A的结果是:10
深入理解二范数
二范数相信大家在本科学线代的时候就已经被灌输了“用来度量向量长度”、“用来度量向量空间中两个点的距离”这两个典型意义。那么在机器学习中,二范数主要有什么重要的应用呢?
我们经常在机器学习的loss函数中加上参数的2范数项,以减少模型对训练集的过拟合,即提高模型的泛化能力。那么问题来了,为什么2范数可以提高模型的泛化能力呢?
首先假设我们model的参数为向量W=[W1, W2, …, Wn], 这个w不仅是模型的参数,更是特征的权重!。换句话说,每个参数Wi,决定了每个特征对决定样本所属类别的重要程度。
这里我们举一个实际例子,假设参数w的维度为5,有以下两种情况:
- 令W1=W2=W3=W4=W5=2
- 令W1=10, W2=W3=W4=W5=0
由二范数公式: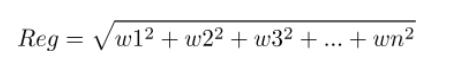
1和2相比,哪个的Reg更小呢?显然前者的值只有20,而后者的值高达100!虽然1和2的所有w的值加起来都等于10。而我们的目标是最小化loss函数,因此需要Reg也要小。由这个例子可以看出,如果我们有10张用于决定类别的票分给各个特征,那么给每个特征分两张票带来的回报要远大于把这10张票分给一个特征!(不患寡而患不均),因此二范数会削弱强特征,增强弱特征。(有点儿劫富济贫的意思)
那么这种方式有什么好处呢?
比如,假设我们在做文本的情感分类任务(判断一段文本是正面还是负面),将每个词作为一个特征(出现该词代表1,否则为0)。可想而知,有一些词本身就带有很强的情感极性,比如“不好”、“惊喜”等。而大部分词是弱极性的,但是多个弱极性的词同时出现的时候就会产生很强的情感极性。比如“总体”“来说”“还是”“可以”在文本中同时出现后基本就奠定了这篇文本的总体极性是正面的,哪怕文本中出现了“很烂”这种强负面词。
因此在二范数的约束下,w这个随机变量的分布会趋向于方差u=0的高斯分布。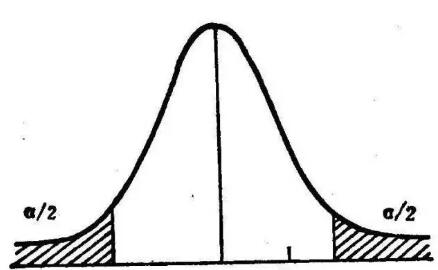
当然,既然是高斯分布,有极少的特征值是特别大的,这些特征就是超强特征,比如“非常好”这个特征一旦出现,基本整个文本的情感极性就确定了,其它的弱特征是很难与之对抗的。所以最小化二范数会让随机变量的采样点组成的向量趋向于期望=0的高斯分布。
所以,如果没有二范数的约束,弱特征会被强特征“剥削”,最终训练完后各个特征的权重很有可能是这样的: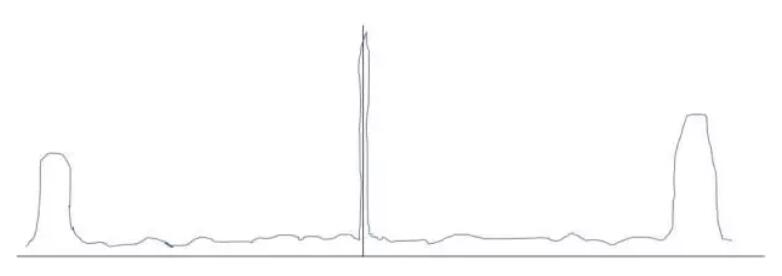
这样会带来什么问题呢?导致模型过分依赖强特征。
- 首先,这样的model拿到测试集上,一旦某个样本没有任何强特征,就会导致这个样本的分类很随机。而如果有了二范数的约束,弱特征们就会发挥它们的作用。
- 其次,这样的model抗噪声能力非常差。一旦测试集中的某个样本出现了一个强特征,就会直接导致其进行分类,而完全不考虑其它弱特征的存在。而如果有了二范数的约束,弱特征们就会聚沙成塔,合力打倒那个强特征的噪声。
那么是不是所有的ML任务加上二范数约束就一定好呢?
答案当然是否定的。在一些ML任务中,尤其是一些结构化数据挖掘任务和特征意义模糊的机器学习任务(比如深度学习)中,特征分布本来就是若干强特征与噪声的组合,这时加上2范数约束反而会引入噪声,降低系统的抗噪性能,导致model的泛化能力更差。
因此,使用二范数去提高机器学习model的泛化能力大部分情况下是没错的,但是也不要无脑使用哦,懂得意义后学会根据任务去感性与理性的分析才是正解。这里有一篇分析机器学习中正则化项L1和L2的直观理解,大家可以借鉴阅读。
