
前言
说起L1、L2范数,大家会立马想到这是机器学习中常用的正则化方法,一般添加在损失函数后面,可以看作是损失函数的惩罚项。那添加L1和L2正则化后到底有什么具体作用呢?为什么会产生这样的作用?本篇博文将和大家一起去探讨L1范数、L2范数背后的原理。
(ps: 文中部分符号未编译出来,大家可移驾csdn上观看此文)
先说结论
L1和L2的作用如下:
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;一定程度上可以防止过拟合
- L2正则化可以防止模型过拟合
理解L1范数
理解L1范数,主要需要理解两个问题。第一是L1产生稀疏矩阵的作用,第二是为什么L1可以产生稀疏模型。
稀疏模型与特征选择
稀疏矩阵指的是很多元素为0、只有少数元素是非零值的矩阵。以线性回归为例,即得到的线性回归模型的大部分系数都是0,这表示只有少数特征对这个模型有贡献,从而实现了特征选择。总而言之,稀疏模型有助于进行特征选择。
为什么L1正则化能产生稀疏模型?
这部分重点讨论为什么L1可以产生稀疏模型,即L1是怎么让系数等于0的。首先要从目标函数讲起,假设带有L1正则化的损失函数如下: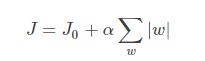
其中J0是损失函数,后边是L1正则化项,$\alpha$是正则化系数,$\omega$是模型的参数。现在我们的目标是求解argmin$\omega$(J),换句话说,我们的任务是在L1的约束下求出J0取最小值的解。假设只考虑二维的情况,即只有两个权值$\omega$1和$\omega$2,此时的L1正则化公式即为:L1 = |$\omega$1| + |$\omega$2|。对J使用梯度下降法求解,则求解J0的过程可以画出等值线,同时L1正则化的函数也可以在二维平面上画出来。如下图: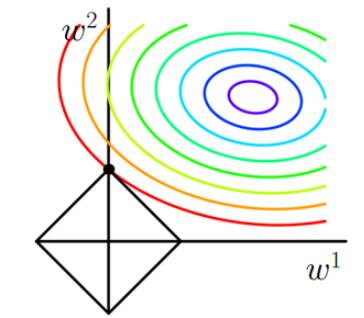
图1 L1正则化
图中等值线是J0的等值线,黑色方形是L1函数的图形,J0等值线与L1图形首次相交的地方就是最优解,我们很容易发现黑色方形必然首先与等值线相交于方形顶点处。可以直观想象,因为L1函数有很多”突出的角“(二维情况下有四个,多维情况下更多),J0与这些角接触的概率远大于与其它部分接触的概率。而这些点某些维度为0(以上图为例,交点处$\omega$1为0),从而会使部分特征等于0,产生稀疏模型,进而可以用于特征选择。
理解L2范数
为什么L2范数可以防止过拟合呢?
要想知道L2范数为什么可以防止过拟合,首先就要知道什么是过拟合。通俗讲,过拟合是指模型参数较大,模型过于复杂,模型抗扰动能力弱。只要测试数据偏移一点点,就会对结果造成很大的影响。因此,要防止过拟合,其中一种方法就是让参数尽可能的小一些。同L1范数分析一样,我们做出图像,如下图所示: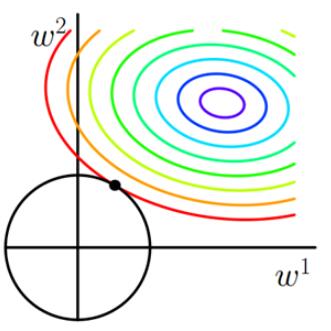
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,没有突出的棱角。因此交点在坐标轴的概率很低,即使得$\omega$1或$\omega$2等于零的概率小了许多。由上图可知,L2中得到的两个权值倾向于均为非零的较小数。 这也就是L1稀疏、L2平滑的原因。
下面我从公式的角度解释一下,为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为\theta, h$\theta$(x)是我们的model,那么LR的损失函数如下: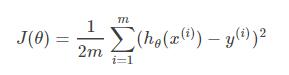
那么在梯度下降法中,最终用于迭代计算参数$\theta$的迭代式为: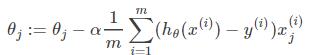
当对损失函数加上L2正则化以后,迭代公式会变成下面的样子: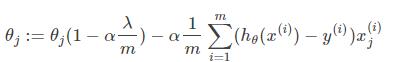
从上式可以看出,与未添加L2正则化的迭代公式相比,每一次迭代,$\theta$j都要乘以一个小于1的因子,从而使得$\theta$j不断减小,因此总的来看,$\theta$是不断减小的。
总结
L1会趋向于产生少量的特征,而其它特征都是0。L2会选择更多的特征,这些特征都会趋近于0。L1在特征选择时非常有用,而L2只是一种防止过拟合的方法。在所有特征中只有少数特征起重要作用的情况下,选择L1范数比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用L2范数也许更合适。
