
前言
在NLP的诸多应用中,有很多应用都有在语义上衡量文本相似度的需求,我们将这类需求统称为“语义匹配”。根据文章长度的不同,语义匹配可以细分为三类:短文本-短文本语义匹配,短文本-长文本语义匹配和长文本-长文本语义匹配。
短文本-短文本语义匹配
短文本-短文本的语义匹配在工业界的应用场景非常广泛。例如,在网页搜索中,我们需要度量用户查询(query)和网页标题(title)的语义相关性;在query推荐中,我们需要度量query和其他query之间的相似度。这些场景都会用到短文本-短文本的语义匹配。由于主题模型在短文本上的效果不太理想,在短文本-短文本匹配任务中词向量的应用比主题模型更为普遍。简单的任务可以使用word2vec、glove等词向量处理。
比如,在query推荐任务中,我们经常需要计算两个query的相似度,例如q1 = “推荐好看的电影”与q2 = “2018好看的电影”。通过简单的Word2vec词向量累加的方式,可以得到这两个query的向量表示,然后直接利用余弦相似度计算两者的相似度即可。对于较难的短文本-短文本语义匹配任务,则可以考虑引入监督信号并利用一些复杂的神经网络模型进行语义相关性的计算。
这里我着重介绍一下DSSM(Deep Structured Semantic Models)的原理。DSSM使用DNN把query和title表达为低维语义向量,并通过cosine距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义向量表达。
DSSM网络结构如图所示: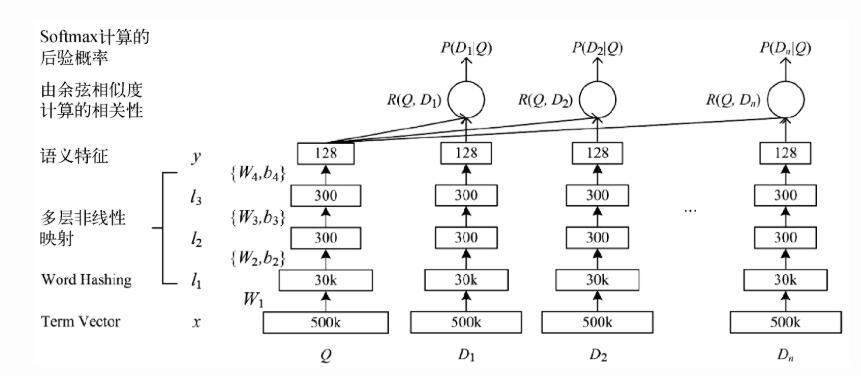
首先输入Query(Q)和展现点击的Doc(D)列表,对Q和D做语义表示,再通过Q-DK的Cosine计算相似度,最后通过softmax来区分点击与否。详细过程如下:
(1)输入层
输入层的事情是把句子映射到一个向量空间并输入到DNN中,这里中文和英文的处理方式大不相同。
- 英文:英文的输入层处理方式是通过词散列(word hashing),即N-Gram的方式,比如可以用letter-trigrams来切分单词。这样做的好处有两个:首先是压缩空间,达到降维的效果,50万个词的one-hot向量空间可以通过letter-trigram压缩为一个三万维的向量空间。其次是增强泛化能力,三个字母的表达往往能代表英文中的前缀和后缀,而前缀后缀往往具有通用的语义。
- 中文:中文的输入层处理方式与英文有很大不同。首先中文分词便是令人十分头疼的事,往往在分词阶段就会引入误差。所以这里我们不分词,而是仿照英文的处理方式,以字为单位处理。同时,由于常用的单字为1.5万左右,而常用的双字则到达了百万级别了。所以出于向量空间的考虑,采用字向量的(one-hot)作为输入,向量空间约为1.5万维。
(2)表示层
DSSM的表示层采用BOW词袋模型,即把字向量的位置信息抛弃了,舍去了先后顺序。当然这样做会有问题,因此也有了后面的改进方法CNN-DSSM和LSTM-DSSM(这里不做介绍)。表示层是一个含有多个隐层的DNN,使用tanh作为激活函数,最终输出一个128维的低维语义向量。
(3)匹配层
Query和Doc的语义相似性可以通过这两个128维语义向量的cosine距离来表示: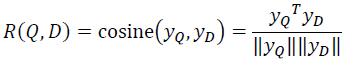
最后通过softmax计算相应概率。
(4)优缺点
优点:DSSM用字向量作为输入既可以减小对分词的依赖,又可以提高模型的泛化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用Embedding的方式(如word2vec)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于word2vec本身属于无监督训练,这样会给整个模型引入误差。而DSSM采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度较高。
缺点:DSSM采用词袋模型,因此丧失了语序信息和上下文信息。同时,DSSM采用弱监督、端到端的模型,预测结果不可控。短文本-长文本语义匹配
短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,在搜索引擎中,我们需要计算一个用户query和一个网页正文content的语义相关度。由于query通常较短,而网页content较长,因此query与content的匹配属于短文本-长文本语义匹配。在计算相似度的时候,我们规避对短文本直接进行主题映射,而是根据长文本的主题分布,计算该分布生成短文本的概率,作为它们之间的相似度。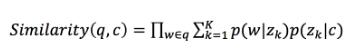
其中q表示query, c表示content,w表示q中的词,Zk表示第k个主题。即引入SentenceLDA,基于SentenceLDA计算query与content的相似度。长文本-长文本语义匹配
长文本-长文本的语义匹配可用于个性化的推荐任务中。基本思路是:通过使用主题模型,得到两个长文本的主题分布,再通过计算两个多项分布的距离来衡量它们之间的相似度。衡量多项分布的距离可以利用Hellinger Distance和Jensen-Shannon Divergence (JSD)。
